Enterprise AI Readiness
A Strategic Framework for Data Preparation
Back to White PapersExecutive Summary
The enterprise technology landscape is undergoing its most significant transformation since the advent of cloud computing. At the epicenter of this shift is Generative AI, led by tools like Microsoft 365 Copilot, which promises to fundamentally redefine how knowledge workers interact with information, automate workflows, and generate value. However, a critical and often underestimated impediment stands between the potential of these technologies and their successful enterprise deployment: the state of the underlying data.
This research paper presents a comprehensive strategic framework for achieving Enterprise AI Data Readiness. We argue that the failure to adequately prepare enterprise data—to transform it from a chaotic, opaque liability into a curated, policy-aligned, and context-enriched asset—is the single greatest barrier to realizing return on investment from AI initiatives.
Our analysis establishes the core concept of AI-Ready Data, defined by three interdependent pillars: Policy-Aligned, Context-Enriched, and Risk-Identified. We demonstrate how an intelligence layer, operating as a middleware between raw enterprise data and AI consumption points, is essential for bridging the gap between AI potential and practical, safe, and economically viable deployment.
Chapter 1: The Copilot Imperative and the Readiness Gap
The Ambition of the Intelligent Enterprise
The vision behind Microsoft 365 Copilot and its counterparts is seductive: an AI assistant that understands an organization's entire corpus of knowledge, synthesizes information across silos, and generates insights, documents, and strategies with unprecedented speed. The promise is one of an "intelligent enterprise," where institutional knowledge is not locked in the minds of individuals or scattered across dormant file shares, but is actively leveraged to accelerate decision-making and enhance productivity.
"Garbage In, Liability Out": The Data Quality Paradox
The fundamental flaw in this vision lies in the implicit assumption that enterprise data is ready. The reality is starkly different. For most organizations, Copilot will not be given access to a well-organized library. It will be unleashed upon a vast, poorly lit, and largely unexplored warehouse, filled with duplicated files, obsolete documents, miscategorized records, and sensitive information exposed without proper controls.
This creates a paradox. The very data that gives Copilot its power is also the source of its greatest potential for failure. When an AI model reasons over low-quality, disorganized data, the results are predictable: hallucinations, inaccurate outputs, confidential data exposure, and a rapid erosion of user trust. The adage "garbage in, garbage out" becomes "garbage in, liability out"in the context of generative AI.
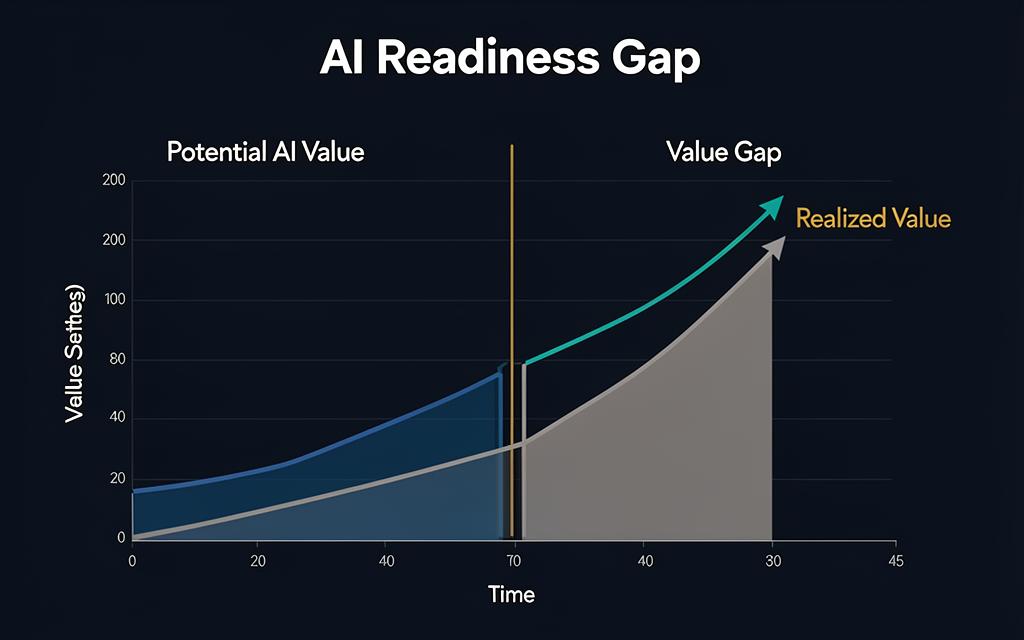
"The enterprise AI 'Value Gap'—the chasm between AI's potential and its actual realized value—will continue to widen for organizations that fail to address data quality as a foundational, pre-deployment concern."
Chapter 2: The Economic Imperative of Readiness
The Financial Impact of Data Readiness
The failure to prepare data for AI is not merely a technical inconvenience; it is an escalating financial liability. This manifests in several key areas:
- The "Stupidity Tax" on Compute and Storage: AI operations, particularly those involving Large Language Models (LLMs), are computationally expensive. The cost of an AI operation is directly proportional to the volume and complexity of the data it processes. Organizations forcing their AI to reason over unoptimized data estates—bloated with duplicates, obsolete files, and trivial content—are paying a significant, recurring "stupidity tax." Every query that must scan through terabytes of ROT to find a megabyte of relevance inflates compute costs dramatically.
- Storage Inflation: The exponential growth of unstructured data, combined with a lack of governance, leads to spiraling storage costs. While storage costs per gigabyte have historically decreased, demand is outpacing these savings, and the shift to high-performance flash storage for AI workloads—which commands a 7-10x premium—is inverting this trend.
"Enterprises demanding 50% year-over-year increases in flash storage for AI workloads are inverting years of storage cost deflation, paying a premium to store data they have never properly evaluated."
Chapter 3: Anatomy of the Data Estate — The Dark Data Crisis
The Data Stratification Model
A useful framework for understanding the enterprise data challenge is to stratify data into three primary categories:
- Business-Critical Data: Information that is actively used for ongoing operations, decision-making, and is subject to defined access and retention policies. This is the "high-value" data that AI should ideally focus on.
- Redundant, Obsolete, and Trivial (ROT) Data: Duplicate files, outdated versions, temporary files, and information with no remaining business value. This is data that should be systematically identified and purged.
- Dark Data: Information that is collected and stored by an organization but is never analyzed or used for any purpose. It exists in a state of neglect, its contents and value entirely unknown.
"Industry research consistently indicates that up to 85% of all data stored by enterprises falls into the ROT or Dark Data categories."
The Mechanics of ROT Accumulation
ROT is not a static problem; it is an actively growing liability. It accumulates through predictable organizational behaviors:
- Versioning Anarchy: Without formal version control, users create multiple copies of documents ("Report_Final," "Report_Final_v2," "Report_FINAL_REALLY_FINAL")
- Orphaned Data: Data owned by employees who have left the organization often becomes ownerless and drifts into obscurity
- Policy Neglect: Retention policies, if they exist, are often not enforced, allowing data to persist far beyond its legal or business relevance
Dark Data: The Compliance Landmine
Dark Data presents an even more insidious threat. Because its contents are unknown, it is impossible to govern. It may contain outdated PII subject to GDPR/CCPA deletion requests, intellectual property that should be protected, or sensitive communications that could be damaging if exposed. An AI assistant, given broad access, could inadvertently surface this information, leading to regulatory breaches, reputational damage, or litigation.
Chapter 4: The Governance Void in Microsoft 365
The Semantic Index and the "Oversharing" Trap
Microsoft 365 Copilot's power derives from its use of the Microsoft Graph and the Semantic Index, which map relationships between users, content, and activities across the M365 ecosystem. Copilot inherently respects existing access controls; it will only show a user information they already have permission to see.
The critical vulnerability lies in the definition of "already have permission to see." In many organizations, file sharing permissions are notoriously overly permissive. Historical decisions to share a SharePoint site with "everyone in the organization" or to place sensitive documents in broadly accessible Teams channels now become vectors for AI-driven data exposure.
"Research indicates that up to 90% of documents classified as 'business-critical' may be shared with parties outside the C-suite who have no legitimate need for access."
Labeling Fatigue and Failure
Microsoft Purview offers a framework for sensitivity labeling, intended to classify documents by their confidentiality level. However, implementation often falters on the rocks of user behavior. Manual labeling is inconsistent and prone to human error. Employees, focused on their primary tasks, often neglect to apply labels, apply them incorrectly, or resist the additional friction in their workflow.
The "Copilot Launchpad" Fallacy
A common, yet dangerously flawed, approach is to attempt to retrofit governance around AI deployment. The logic follows: "Let's deploy Copilot to a limited pilot group and see what problems arise, then fix them." This reactive approach is fundamentally inadequate. It treats AI as a diagnostic tool for data governance rather than a powerful system that demands a governed data environment as a prerequisite.
Chapter 5: The Three Pillars of AI-Ready Data
True AI readiness is not achieved by a single action but through a holistic transformation of the data estate. We define AI-Ready Data as data that is simultaneously:
1. Policy-Aligned
Data must be organized according to the organization's established policies for retention, compliance, and utilization. This means:
- Data subject to specific retention schedules (e.g., 7-year financial records, 3-year HR documents) is identified and tagged accordingly
- Data subject to regulatory mandates (GDPR, HIPAA, CCPA) is flagged and governed to meet specific requirements for access, deletion, and portability
- Data subject to legal holds is immutably preserved and protected from modification or deletion
2. Context-Enriched
Data must possess rich, accurate metadata that provides context. This goes far beyond basic file system attributes (creation date, file type) to include:
- Ownership: Clear identification of the data owner or responsible department
- Classification: The type of document and its purpose (e.g., "legal contract," "marketing material," "technical specification")
- Sensitivity: Assessment of whether the data is confidential, internal-use-only, or public
- Relevance: Indicators of whether the data is current or obsolete
3. Risk-Identified
All data must be scanned and classified for sensitive content, including:
- PII (Personally Identifiable Information): Names, addresses, social security numbers, etc.
- PHI (Protected Health Information): Medical records and health-related data
- PCI (Payment Card Industry): Credit card numbers and financial transaction data
- Intellectual Property: Trade secrets, patents, proprietary research
Chapter 6: The Role of Metadata and Semantic Context
Beyond File System Metadata
Native file system metadata (creation date, modification date, author, file size) is a starting point, but it is profoundly insufficient for AI-ready governance. It tells you when a file was created, but not what it is, why it matters, or who should have access to it.
AI-ready metadata requires a layer of semantic enrichment. This involves analyzing the contentof the data to infer its purpose, classify its sensitivity, and link it to relevant organizational entities (projects, clients, departments). This is the transformation from passive, descriptive metadata to active, prescriptive metadata.
The RAG Advantage
The power of semantically enriched metadata becomes most apparent in the context ofRetrieval-Augmented Generation (RAG). RAG is the architectural pattern behind Copilot's ability to answer questions about an organization's data. When a user asks a question, the AI first retrieves relevant documents from the data estate, then uses those documents as context to generate a response.
The quality of the retrieval step is paramount. If the retrieval mechanism cannot accurately identify the most relevant documents, the generation step will suffer. Rich, high-fidelity metadata acts as a precise signpost, guiding the RAG system to the right information quickly and accurately.
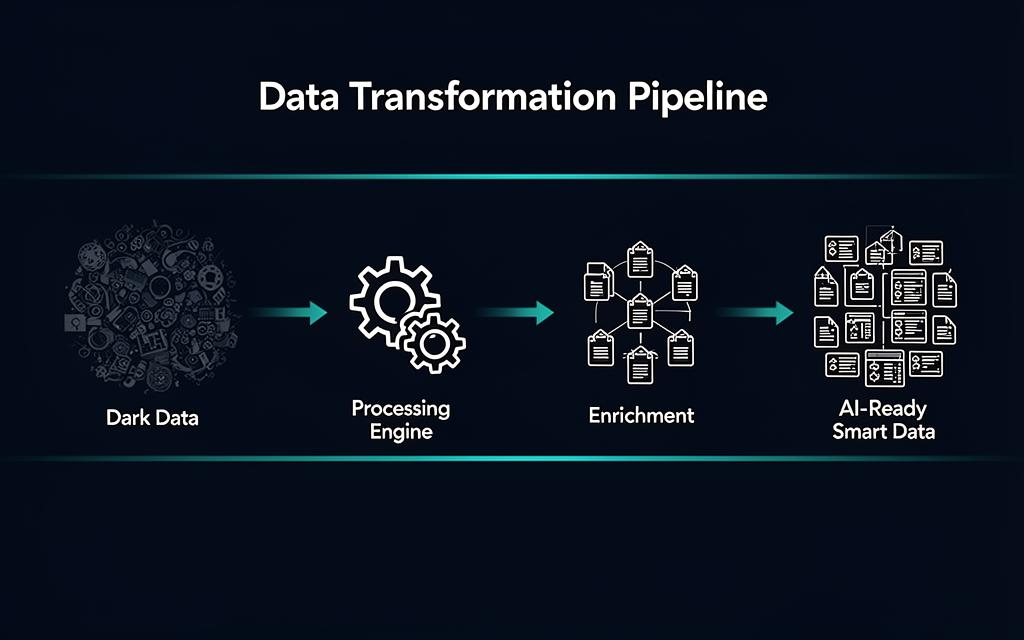
Chapter 7: Architecture of an Intelligence Layer
The Middleware Concept
The solution to the AI readiness challenge is not to replace existing Microsoft services but to augment them with a dedicated intelligence layer. This layer operates as middleware, sitting between the raw data estate (SharePoint, file shares, Exchange, archives) and the AI consumption points (Copilot, analytics platforms, OneLake).
Its function is to act as a sophisticated "data refinery." Raw, unprocessed data enters one side; curated, enriched, policy-aligned, AI-Ready data exits the other. This is not a data migration or duplication effort; it is an in-place transformation that enriches metadata and enforces policy without disrupting the location or structure of existing data.
The "Air Gap" Approach to Security
A key architectural principle is to maintain an "air gap" between the intelligence layer and the live AI environment. The data refinery performs its analysis and enrichment in a controlled environment. Only after data has been processed, classified, and approved does it become visible to or consumable by AI tools.
This approach prevents the common failure mode of exposing raw, unanalyzed data to AI and hoping for the best. It ensures that risk identification happens before AI access, not as a consequence of it.
Chapter 8: Smart Data Refinery — The Mechanism of Identification
At the heart of the intelligence layer is the Smart Data Refinery engine. This is not a simple file scanner; it is a sophisticated analytical system that applies multiple lenses to every piece of data:
ROT Detection
Using techniques such as hash comparison, content fingerprinting, and temporal analysis, the system identifies:
- Exact and near-duplicate files
- Documents that have not been accessed or modified within policy-defined periods (staleness indicators)
- Temporary files, cache files, and system-generated clutter
Sensitivity Scanning
Employing pattern matching, regular expressions, and machine learning classifiers, the system identifies sensitive data elements within documents, including:
- Social Security Numbers, National ID Numbers
- Credit Card Numbers, Bank Account Numbers
- Medical Record Numbers, Health Condition Keywords
- Confidential classifications, password files
Contextual Inference
By analyzing document structure, embedded metadata, and content patterns, the system infers:
- Document type (contract, invoice, proposal, memo)
- Departmental affiliation
- Project or client association
- Relevance to specific compliance regimes (GDPR data subject, HIPAA-covered entity)
Actionable Policies for Smart Data
The output of Smart Data Refinery is not merely a report; it is a set of actionable metadata enrichments that can drive automated policy enforcement. Identified ROT can be flagged for deletion campaigns. Sensitive data can be automatically quarantined or subjected to enhanced access controls. Documents can be tagged with retention labels that trigger automated archival or deletion workflows.
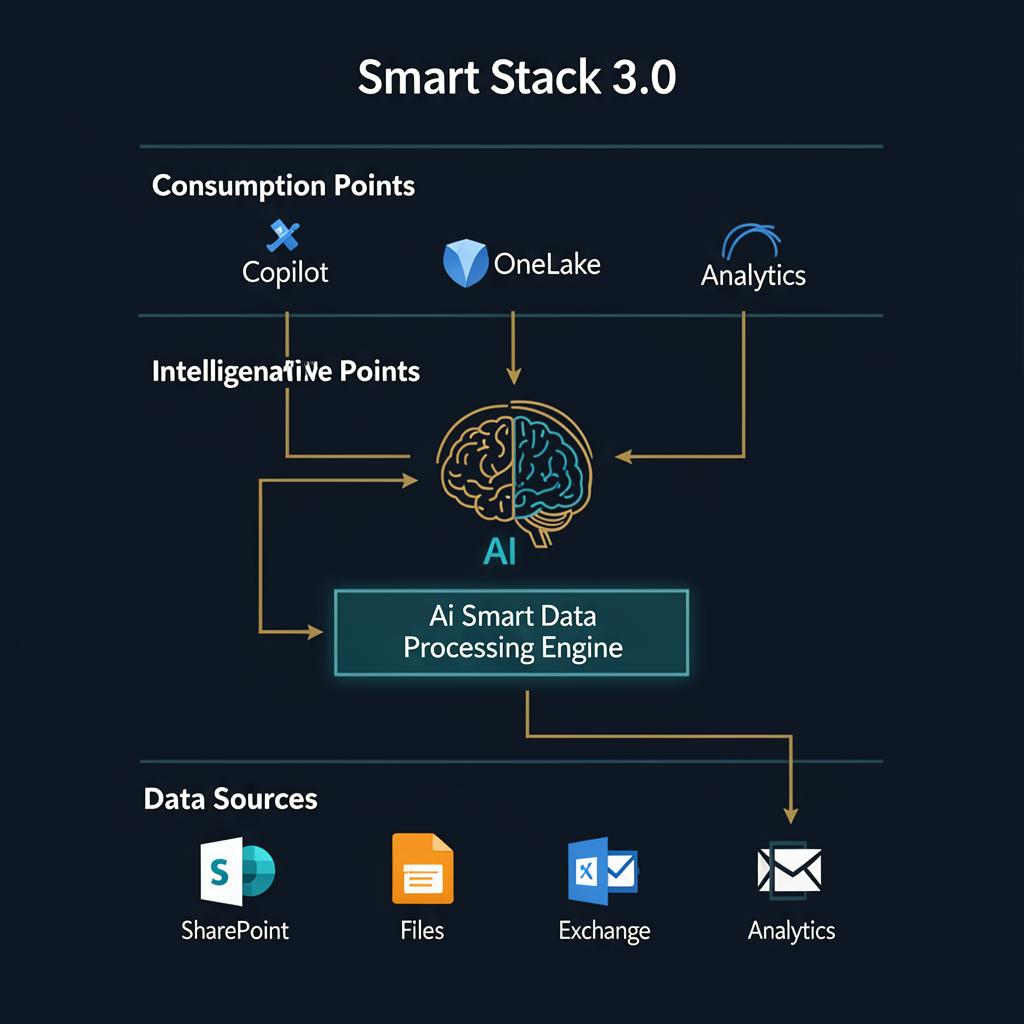
Chapter 9: Smart HUB — The Intelligence Control Plane
From Refined Data to Activated Intelligence
Once data has been processed by the Smart Data Refinery and organized into Smart Data Collections, the Smart HUB serves as the operational control plane. It activates these collections — staging, governing, sharing, and operationalizing enriched metadata across the enterprise and into Microsoft AI systems.
The basic premise of the Smart HUB is elegant: Elasticsearch organizes meaning, Nextcloud enables action, and MCP makes AI use safe. This architecture delivers a fundamentally different approach than raw data lake ingestion.
Smart Data Mirroring: The Controlled Feed to OneLake
Smart Data Mirroring offers a fundamentally different approach to populating Microsoft OneLake. Instead of migrating raw data, it mirrors only the data that has been fully processed by the Smart Data Refinery. This means:
- ROT-Free: Redundant and obsolete data is filtered out before reaching OneLake
- Sensitivity-Aware: Data containing unresolved sensitive content is either excluded or redacted
- Metadata-Rich: All mirrored data carries the enriched metadata generated by the intelligence layer
- Policy-Aligned: Only data approved for AI consumption under the organization's governance policies is included
The Governed AI Interface: MCP
Through the Model Context Protocol (MCP), AI agents do not roam enterprise repositories freely. Instead, they query Smart Data Collections, retrieve only authorized content, and maintain full provenance back to source systems. This significantly reduces hallucination, accidental exposure, and compliance risk while improving AI accuracy and trustworthiness. Every response can be traced back to the exact source, version, and policy context of the underlying data — an essential requirement for regulated industries and high-stakes legal use cases.
Delta Tables and Microsoft Fabric
Smart Data Mirroring is designed to output data in formats optimized for AI consumption, including Delta tables — the preferred format for Microsoft Fabric. This ensures seamless integration with downstream analytics and AI workloads, maintaining a single source of truth that is both high-quality and performant.
Chapter 10: Legacy Archives and the Compliance Imperative
The Proprietary Format Barrier
Many organizations have invested decades in archiving systems for email, documents, and other communications. These legacy archives, often stored in proprietary formats, represent a significant repository of institutional knowledge. However, they are frequently inaccessible to modern AI tools, which expect data in open, searchable formats.
Simply abandoning these archives is not an option. They often contain information subject to long-term retention mandates and may be critical for legal discovery, compliance audits, or historical research.
Compliance as a Service
A comprehensive data readiness strategy must include a pathway for legacy archive integration. This involves:
- Format Normalization: Converting proprietary archive formats into modern, searchable, and AI-consumable structures (e.g., standard email formats, indexed document stores)
- Metadata Enrichment: Applying the same Smart Data Refinery to archived content, identifying sensitivity, classifying document types, and enriching metadata
- Compliant Journaling: Ensuring that all archive access and processing maintains a full audit trail for regulatory defensibility
Converting Archives to Accessible Repositories
The goal is to transform closed, opaque archives into accessible, governed repositories that can contribute to AI-powered insights without compromising compliance. This unlocks decades of institutional knowledge for modern AI applications while maintaining the chain of custody and immutability required by regulators.
Chapter 11: The Financial Model of Data Governance for AI
Token Economics and Variable Costs
AI operations, particularly those involving LLMs, are often priced on a per-token or per-query basis. The cost of answering a single query is directly influenced by the volume of data that must be retrieved and processed to generate a response.
Consider two scenarios:
Scenario A: Dirty Data
Copilot must search through 10TB of unoptimized file shares. 60% of the data is ROT. Query latency is high. Each query consumes significant compute resources, resulting in escalating variable costs per user.
Scenario B: Smart Data
Copilot searches an optimized, mirrored dataset of 4TB (ROT eliminated). Data is pre-indexed with high-fidelity metadata. Query latency is low. Each query is efficient, resulting in predictable and lower variable costs per user.
The delta between these scenarios can represent a 40-60% reduction in ongoing AI operational costs, transforming AI from an unpredictable expense into a managed, cost-effective capability.
Storage Optimization Opportunity
Beyond compute savings, systematic ROT identification and remediation offers direct storage cost reduction. Organizations that purge 60% of their ROT can expect a corresponding decrease in storage footprint and associated costs. When combined with tiered storage strategies (archiving cold data to lower-cost storage), savings compound significantly.
Chapter 12: Case Study — General Electric
To illustrate the practical application of the data readiness framework, we examine a large-scale engagement with General Electric, a global industrial conglomerate with a complex, historically accumulated data estate.
The Challenge
GE faced a significant data management challenge. Over decades, the organization had accumulated massive volumes of unstructured data across multiple divisions and systems. This data sprawl was characterized by:
- Peta-scale data growth with no unified governance
- Significant volumes of suspected ROT
- High storage and operational costs
- Increasing pressure to prepare for AI-driven transformation
The Execution
A phased data optimization and readiness initiative was implemented, involving:
- Comprehensive Scanning: Petabytes of data across file shares and archives were scanned using the Smart Data Refinery engine
- ROT Identification and Remediation: Approximately 25% of the scanned data was identified as ROT and marked for deletion
- Storage Re-tiering: 4PB of data was migrated to more cost-effective storage tiers based on access patterns and sensitivity
- Cloud Migration Preparation: 6PB of data was prepared for migration to cloud storage, with full metadata enrichment
The Result
The initiative delivered substantial, measurable outcomes:

"$30M reduction in storage-related costs achieved through systematic ROT elimination, storage re-tiering, and cloud optimization—a 60% reduction in the operational data footprint."
- $30M Annual Savings: Reduction in storage-related costs
- 60% Footprint Reduction: Dramatic decrease in the operational data estate
- AI-Ready Foundation: Remaining data was enriched, classified, and prepared for AI consumption
- Accelerated Cloud Adoption: Clean, governed data enabled faster, lower-risk cloud migration
Chapter 13: Operationalizing the Framework
Achieving AI data readiness is not a one-time project; it is an ongoing operational capability. The following phased approach provides a roadmap for implementation:
Phase 1: Discovery and Assessment (The Scan)
- Deploy scanning capabilities across file shares, SharePoint, archives, and other unstructured data repositories
- Generate comprehensive inventory of data assets, including volume, type, age, and access patterns
- Identify initial estimates of ROT, sensitive data, and governance gaps
- Establish baseline metrics for cost, risk, and AI readiness
Phase 2: Remediation and Optimization (The Cleanse)
- Execute ROT deletion campaigns, with appropriate stakeholder notification and approval workflows
- Implement storage re-tiering based on access frequency and business value
- Resolve orphaned data ownership, reassigning or archiving as appropriate
- Enforce retention policies, deleting data that has exceeded its mandated lifecycle
Phase 3: Enrichment and Classification (The Context)
- Apply Smart Data Refinery to remaining data, enriching metadata with classification, sensitivity, and ownership
- Tag data with policy-aligned retention and access labels
- Generate Smart Data Collections: curated, governed datasets ready for specific use cases (legal, compliance, AI)
Phase 4: Activation (The Feed)
- Configure Smart HUB to mirror approved Smart Data Collections to OneLake or other AI consumption platforms via pointer-based Smart Data Mirroring
- Establish continuous synchronization using the MCP interface, ensuring new data entering the environment is processed and enriched in real time
- Enable AI tools — Copilot, analytics platforms, autonomous agents — to operate on curated Smart Data Collections rather than raw data repositories
- Monitor AI performance, user trust metrics, and cost efficiency through Purview Audit logs, refining policies and collections as needed
Conclusion: From AI Ambition to AI Execution
The promise of enterprise AI is immense. Tools like Microsoft 365 Copilot offer a vision of transformed productivity, where institutional knowledge is readily accessible and actionable. However, this promise cannot be realized without confronting the foundational challenge of data readiness.
Organizations that attempt to deploy AI over unprepared data estates will experience predictable failures: hallucinations, data exposure, eroded user trust, and spiraling costs. Those that invest in transforming their data—eliminating ROT, enriching metadata, identifying risk, and aligning with policy—will unlock the true potential of AI and gain a durable competitive advantage.
The framework presented in this paper—defining AI-Ready Data as Policy-Aligned, Context-Enriched, and Risk-Identified, and operationalizing it through an intelligence layer—provides a clear, actionable roadmap for achieving this transformation.
The message is clear: AI success is data success. Prepare your data, or prepare to fail.
Works Cited
- Microsoft. "Microsoft 365 Copilot: How it works." Microsoft Learn. learn.microsoft.com
- Gartner. "Data Management Research: Dark Data and ROT Statistics." Gartner Research.
- Microsoft. "Semantic Index for Copilot." Microsoft Learn. learn.microsoft.com
- Microsoft. "Microsoft Purview Information Protection." Microsoft Learn. learn.microsoft.com
- International Association of Privacy Professionals (IAPP). "GDPR and CCPA Compliance Frameworks."
- Health Insurance Portability and Accountability Act (HIPAA). "Protected Health Information Guidelines."
- Payment Card Industry Security Standards Council (PCI SSC). "PCI Data Security Standard."
- Microsoft. "Microsoft Fabric and OneLake Overview." Microsoft Learn. learn.microsoft.com
- Lewis, Patrick, et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." arXiv preprint arXiv:2005.11401 (2020).
- Microsoft. "Delta Lake format in Microsoft Fabric." Microsoft Learn. learn.microsoft.com
- Zantaz Data Resources. "Smart Stack 3.0 Technical Architecture." Internal Documentation, 2026.
- IDC. "Worldwide Global DataSphere Forecast." IDC Research.
- Veritas Technologies. "The Global Databerg Report." Veritas Research.
- Storage Industry Networking Association (SNIA). "Flash Storage Market Analysis and Pricing Trends."
- McKinsey & Company. "The State of AI in 2024: Gen AI Adoption and Impact."
- Deloitte. "State of AI in the Enterprise." Deloitte Insights.
- Aberdeen Group. "The Business Value of Data Governance."
- Ponemon Institute. "Cost of a Data Breach Report 2024."
- General Electric. "Data Optimization Initiative: Case Study Results." Internal Report, 2025.
- Federal Rules of Civil Procedure. "Rule 37(e): Failure to Preserve Electronically Stored Information."
Related Reading
Precision Governance
Strategic manifesto and technical roadmap for CISOs and CCOs addressing the Purview Paradox — how to govern exabytes of legacy data for safe AI deployment using the Trusted Data Refinery and Trusted Data Portal architecture.
ResearchThe Missing Intelligence Layer
Comprehensive research establishing the Microsoft Companion category as a mandatory architectural necessity for the AI era. Covers AI failure modes, the Trusted Data Portal with Elasticsearch, Nextcloud, and MCP, cost analysis, and ROI validation.
Ready to Transform Your Data?
See how Zantaz's Smart Stack 3.0 can make your enterprise AI-ready.